In this series of articles and tutorials I’ll be discussing some of the various technologies and strategies available for increasing the performance of science-related applications. Some of the items that will be discussed are Mac Only (e.g. Accelerate framework) while others will be generally applicable (e.g. OpenMP). Most of the articles/tutorials that go beyond compiler level optimization strategies, and therefore compiler related performance tuning will be discussed within the context of specific examples rather than as a dedicated item.
In the first part of this series I’ll begin by presenting an overview of the Accelerate framework, what it does and ways to begin using it immediately. In the second part of the tutorial I’ll provide specific examples of how to use Accelerate in your own code. The third part of the initial portion of the series I’ll then show you how to extend Accelerate to tackle calculations that it doesn’t perform out of the box and how to “accelerate” the Accelerate framework. So let’s begin…
What do I need an umbrella for? It’s not raining.
The Accelerate framework is actually referred to as an umbrella framework because it encapsulates both vecLib and vImage into a single framework on the system. In later parts of the series you’ll see how having an umbrella framework can help simplify using the package. Accelerate ships with every copy of Mac OS X and originally shipped as a standalone framework referred to as vecLib; a set of high performance numerical libraries. Because it is present in every copy of Mac OS X, there is no need to include additional libraries with your application if they link against it. Around the time of Panther (Mac OS 10.3) a second component was added called vImage which provided a number of high performance routines for image processing applications. Both frameworks are continually developed, as new versions of Mac OS X are released, with new functionality added or with improvements to previous implementations.
Accelerate resides in /System/Library/Frameworks along with the other public frameworks, such as Cocoa, Carbon, Quartz, etc. Figure 1 shows the relationship of vecLib and vImage to Accelerate. You’ll notice from the figure that vecLib is comprised further of a set of separate libraries. vecLib provides linear algebra algorithms (BLAS/LAPACK), DSP algorithms (such as FFTs in vDSP), and a set of “miscellaneous” functions that perform various numerical operations that don’t fit squarely in the other libraries (vMisc). Accelerate includes scalar and (where appropriate) vectorized versions of the routines that utilize the SIMD units on the CPUs (SSE on Intel and Altivec on PowerPC G4/G5). The appropriate version of the routine will be selected at runtime depending on the CPU type. Additionally, for many of the functions both single and double precision versions are available as well.
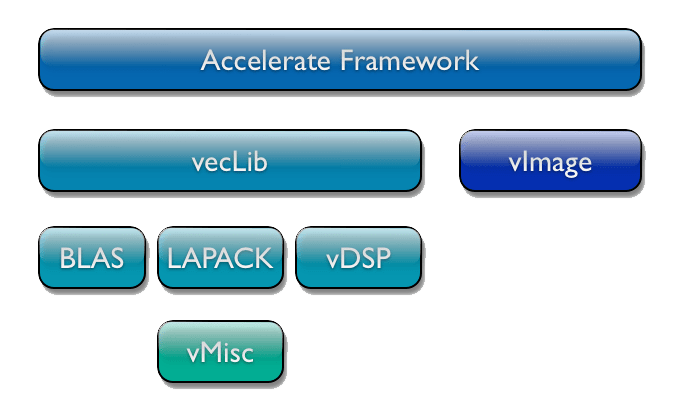
Figure 1
That’s a vec(x)ing question!
Throughout this series I’ll be talking about vector this and SIMD that so perhaps a brief discussion is required. In this case, we are not referring to the concept of vectors that are used in physics and mathematics classes (that is, things that many of us had nightmares about in high school). Vector units (also referred to as SIMD units for Single Instruction Multiple Data) are specialized pieces of hardware that exist on CPU’s for performing a set of similar operations (such as add, subtract, multiply) on a lot of data at the same time. These units have common names that you’ve probably heard before (MMX, SSE, SSE2, Altivec etc.) and are present on almost every modern commodity CPU.
As a simple example (Figure 2), say you had two large arrays of numbers that you wanted to add together. In the scalar portion of the CPU each pair of numbers in the two arrays would be added together in series one after the other. In the vector unit some multiple of those pairs (usually, 4, 8 or 16) would be added simultaneously. That is for each addition instruction (single instruction) you’d perform the same operation on multiple pairs (multiple data). Processing up to 16x the amount of data that you can process in the same time it takes to process a single element is a big performance win. Of course there are no free lunches (unless you happen to be going to Friday afternoon journal club) and there are limitations to the types of data that can be processed, and we will discuss those limitations in later portions of the series.

Figure 2
You’re lips are moving, but all I hear is BLAS, BLAS, BLAS!
As mentioned above vecLib, the first component of Accelerate, consists of multiple libraries. We’ll begin our introduction by looking at the various header files for vecLib (Figure 3).
Figure 3
cblas.h/clapack.h – C interface for the Level 1, 2, and 3 BLAS routines.
vBLAS.h – FORTRAN interface for the Apple provided BLAS functions.
vectorOps.h – Vector implemented versions of the BLAS routines.
vBigNum.h – Algebraic and logical operations on large numbers (128-, 256-, 512-, 1024-bit quantities)
vBasicOps.h – Basic algebraic operations. 8-, 16-, 32-, 64-, 128-bit divides, saturated addition and subtraction, shift/rotate etc…
vfp.h – Trancendental operations (sin, cos, exp etc) on single vector floating point quantities.
vDSP.h – DSP algorithms including FFTs, signal clipping, filters, type conversions.
vForce.h – Transcendental operations on arrays of floating point quantities.
Each of the header files lists all of the publicly accessible operations in vecLib that can be used by any developer on Mac OS X. Of course since this is an umbrella framework, you need not worry about which header files to include if you are spinning your own code as Accelerate.h covers both the vecLib and vImage frameworks, which in turn cover their own respective header files. A simple include statement of <Accelerate/Accelerate.h> in your application will resolve the madness for you.
A picture is worth a thousand words.
The second component of Accelerate is vImage, which can be used for image processing applications. The organization of vImage is more straightforward than vecLib. vImage consists of routines for performing image data type conversions, convolutions, geometric transformations etc (Figure X). vImage, like vecLib, has scalar and vector versions of the routines. A description of the headers for vImage is provided below.
Figure 4
Alpha.h – Alpha compositing functions.
Conversion.h – Converts from one format to another such as Planar8 to PlanarF and ARGB8888 to Planar8.
Convoluton.h – Image convolution routines with user specified kernels.
Geometry.h – Geometric transformations. Rotate, scale, affine warp, shear.
Histogram.h – Histogram calculation, equalization, contrast stretch.
Morphology.h – Dilate, erode, min, max.
Tranform.h – Matrix multiply, gamma adjustment, lookup tables.
As with vecLib, vImage prototypes are accessible from your code by using the main Accelerate header file.
To bit or not to bit.
Starting with Mac OS 10.4, Accelerate is almost entirely 64-bit capable (vDSP on PowerPC is not currently 64-bit). vDSP aside, the rest of Accelerate is 64-bit capable. On Intel based Mac’s Accelerate is 64-bit through and through. In Leopard Accelerate will be fully 64-bit for PowerPC and Intel.
Accelerate…your research.
Ok. Now that we know what is in Accelerate, how can you get access to some of the functionality without writing any code (we’ll write some code in the next part of the tutorial)? Well, if you are using an application that already links against Accelerate, you are already using it, congratulations. Seriously though, because Accelerate includes optimized versions of BLAS/LAPACK (based on ATLAS) any application that links against an external BLAS/LAPACK library can begin using Accelerate with a few linker flags.
Example 1: Simple linking of a small app.
prompt> gcc -o myprog myprog.c -framework Accelerate
prompt> gfortran -o myprog myprog.f -framework Accelerate
Assuming myprog.c/.f makes calls to BLAS/LAPACK routines, you are done.
Example 2: Linking in via configure.
Using configure/make you can often set the link step to use Accelerate instead of another external BLAS/LAPACK library.
setenv LDFLAGS “-Wl,-framework -Wl,Accelerate” (csh/tcsh)
export LDFLAGS=” -Wl,-framework -Wl,Accelerate” (sh/bash)
Then run configure as normal. This assumes that there isn’t a library providing those symbols in a path that gets searched before Accelerate. As we discussed in our Apple Transition To Intel Report (based on meetings with Apple in March), in the future, libblas.dylib and liblapack.dylib will be directly accessible from /usr/lib, providing a simple means for configure/make style install mechanisms to identify the Mac OS X versions of the libraries.
Example 3: Xcode
1) In an Xcode project window, right click on the Frameworks folder
2) Select Existing Frameworks… from the contextual menu
3) Navigate to /System/Libraries/Frameworks and select Accelerate.framework
That’s it!
And we’re done…for now.
So that is our higher level overview of Accelerate. In the next installation we’ll actually write some code that uses Accelerate. Over the course of the series I’ll show you how to tie Accelerate into other Mac OS X technologies (such as Cocoa) that you can use to quickly prototype algorithms and image processing routines. In the meantime you may want to check out the following references for more information about performance related topics on Mac OS X.
Leave a Reply